codyze-evaluator
Methodology
This chapter describes the methodology which we use to assess the compliance of an OpenStack instance with respect to security goals. The high-level architecture and workflow is presented in the chapter Goals, but we provide a short recap here:
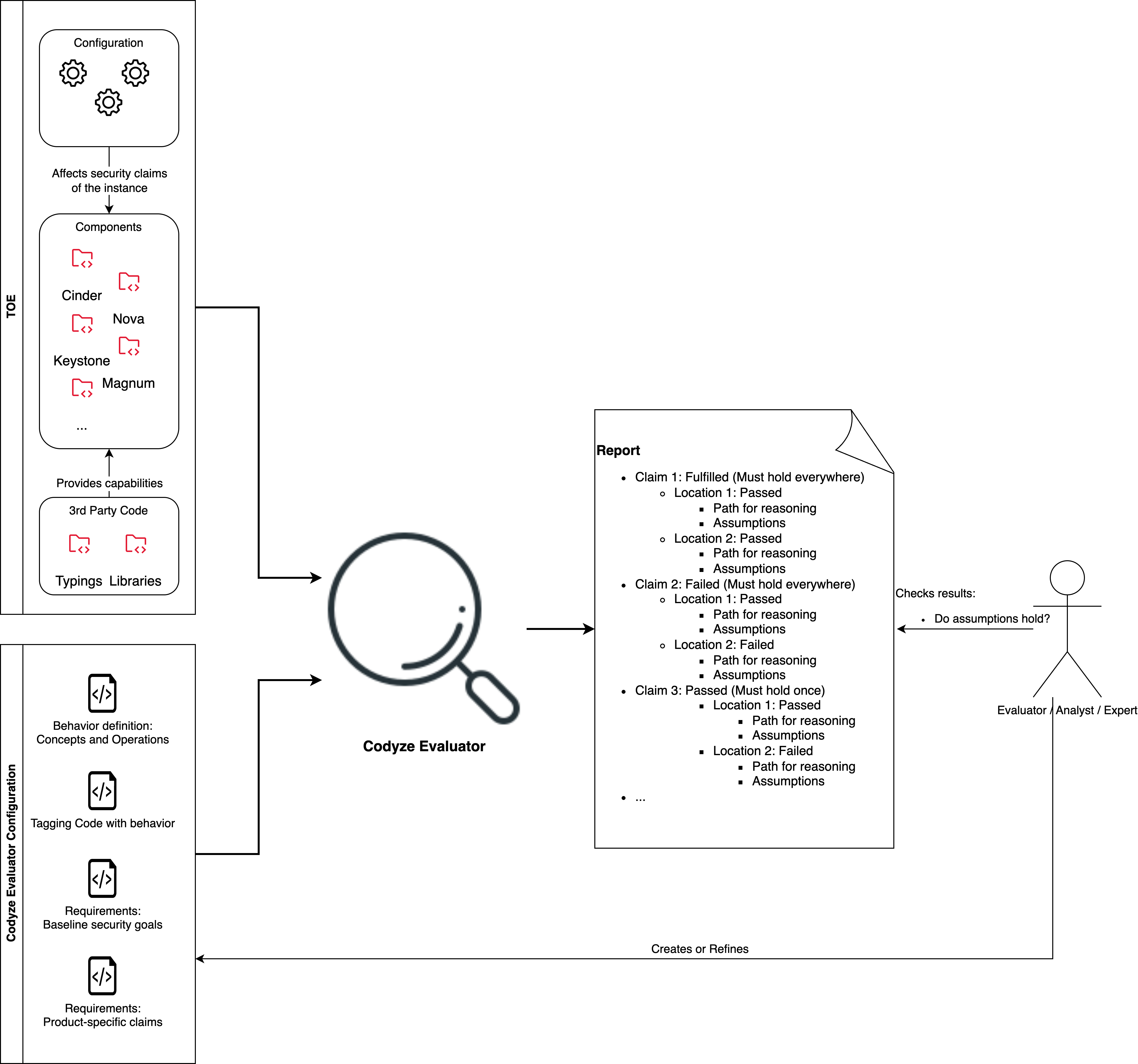
As the overview of the workflow shows, the Codyze Evaluator consists of two major inputs:
- The TOE is a concrete instance of the software product. In the case of OpenStack, it consists of various components of OpenStack at a specific software version, several third party libraries (i.e., python libraries), and a specific configuration of the whole system. The TOE implements the security claims by its security features.
- The Codyze Evaluator Configuration is the configuration of the Codyze Evaluator. It consists of a set of security goals, a set of concepts and operations, and a set of rules which define how to tag the code base with these concepts and operations.
!!! note “Relation to Common Criteria Evaluation”
To retrieve the Codyze Evaluator Configuration, the evaluator can exploit the following resources:
* The Protection Profile to which the TOE claims compliance.
* The Security Target of the TOE, in particular the Security Functions (SF), Security Functional Requirements (SFRs), and the details on their implementation.
Codyze Evaluator: Compliance Checking Tool
Internally, the Codyze Evaluator translates the TOE to a Code Property Graph (CPG) and uses this representation for subsequent static analysis of the TOE. The Codyze Evaluator Configuration follows two goals: First, it adds semantic information to the program code and second, it queries the CPG to evaluate if the security goals are met. As the implemented static analyses can introduce false positive and false negative findings, the CPG aims to explicitly state assumptions which are made during the translation and analysis. These can be introduced by general assumptions and limitations of static analysis tools, ambiguous and unclear language features, missing implementation details, imprecise or unsound analysis methods, or the usage of heuristics for certain tasks.
This section describes
- the CPG as representation of source code,
- how we integrate the configuration of the TOE,
- the CPG’s extension to model program semantics,
- the meaning of assumptions in the context of the analysis, and
- how the compliance checks are run as queries on the CPG.
The Code Property Graph (CPG) as Source Code Representation
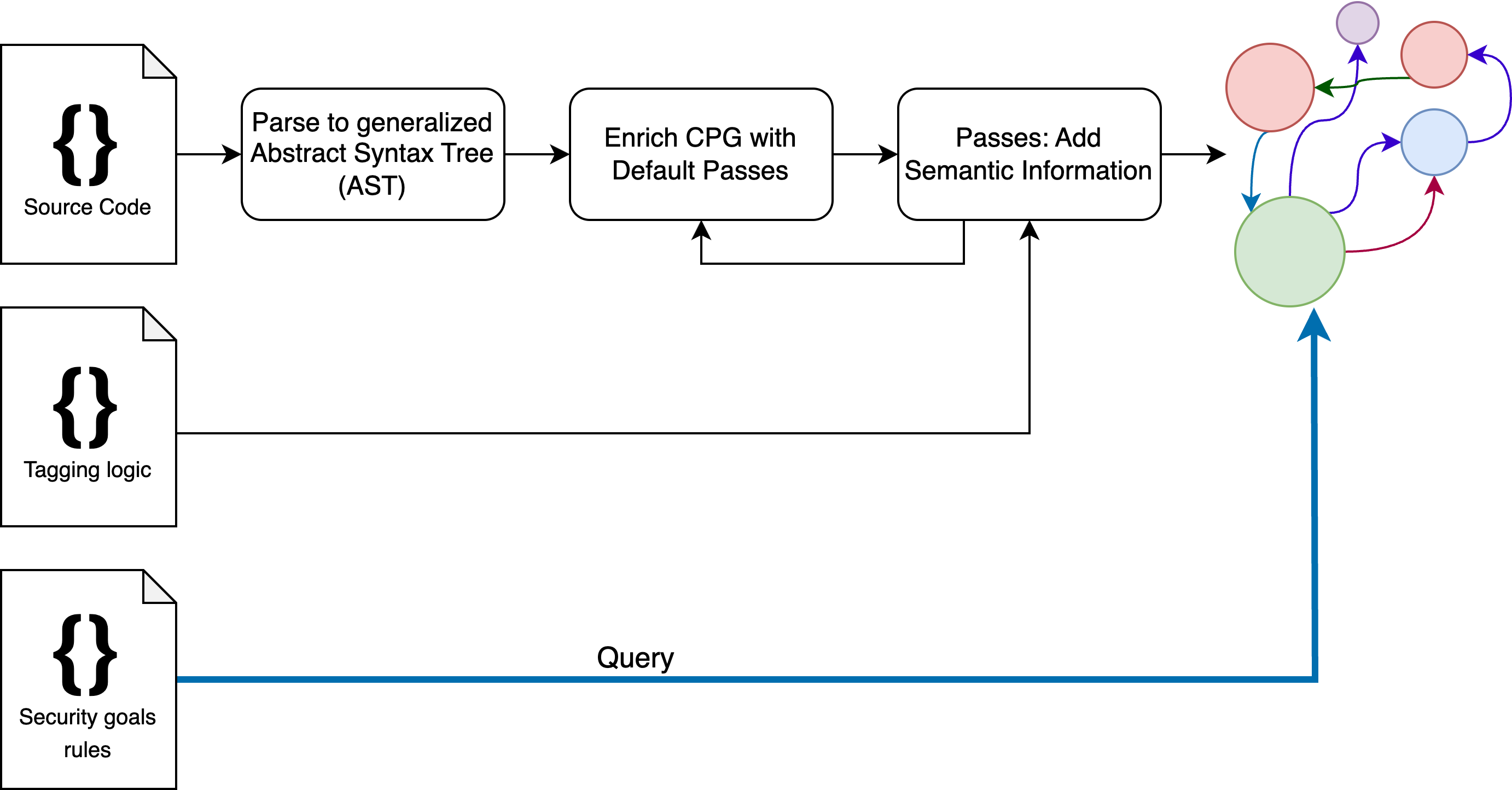
Internally, the Codyze Evaluator translates the TOE’s code base and configuration to a Code Property Graph (CPG). This is a graph representation abstracting from different programming languages, and including various information which are required for static code analysis. In particular, it includes the following sub-graphs:
- The evaluation order graph (EOG) determines the order in which statements and expressions may be traversed at run-time
- The dataflow graph (DFG) summarizes data dependencies between different statements and expressions
- The call graph (CG) contains the function calls and possible call targets
- The control dependence graph (CDG) summarizes if reaching a statement depends on the evaluation of a certain condition
- The program dependence graph (PDG) combines the CDG and DFG
Furthermore, it resolves the type hierarchy containing the inheritance relations between classes and interfaces, types of expressions, and references and usages between variables and expressions.
For a complete overview of the CPG’s implementation details, we refer to the documentation of the CPG library1.
To provide an abstraction from the programming language, the nodes and edges of the CPG include information about specific features of the programming language. Examples for this are that the EOG may differ for similar operations depending on the language, or types with the same name have different properties, e.g., when considering mutable vs. immutable types, the size of numeric types, or signed vs. unsigned numbers. Prior research2 has shown that this representation minimizes the loss while still providing an abstract interface for subsequent analyses.
The CPG library used in the Codyze Evaluator supports python as programming language, which is used for developing the OpenStack components.
Each module of the TOE is kept in a separate Component inside the CPG.
This simulates that they are separate projects but can communicate via specific interfaces (in the case of OpenStack, these are HTTP calls).
Integration of the Configuration
Besides the code base, the Codyze Evaluator also considers the configuration of the TOE.
E.g., OpenStack is configured via .ini files, which is why the CPG library had been extended with a custom language-frontend parsing these files.
The configuration is then represented in the CPG in a separate Component which holds the hierarchy of the sections in the .ini files, as well as the key-value pairs.
Custom Passes connect the usage of configurations within the source code of the TOE’s components with the values held in the configuration.
Modelling Semantics via Concepts and Operations
While the basic implementation of the CPG provides a representation of the source code’s syntax, it does not provide any semantic information nor an abstraction thereof.
As most requirements, however, are not directly related to the syntax of the code but rather to its semantics, enriching the CPG with semantic information can greatly generalize queries checking for certain requirements.
To enable this, we extended the CPG with so-called Concepts and Operations.
These model semantic information, either in a general way (Concept) or by abstracting a specific behavior/action of the source code (Operation).
The Concepts and Operations are added to the CPG as nodes, which are, however, not part of the existing source code (we use the term OverlayNode for this) and are connected to the existing nodes of the CPG via specific edges (overlayEdges and underlyingNode), as well as the EOG and DFG.
The Concepts and Operations are defined in the module cpg-concepts but, as this list is not complete for all cases (i.e., any analysis can require additional semantic information), it is possible to extend these via the Codyze Evaluator configuration.
The mapping of source code to the semantic information can be implemented as custom passes or as part of the Codyze Evaluator configuration via a specific domain specific language (DSL).
!!! info “Connecting different components of the TOE”
As different components of a TOE can interact with each other via HTTP calls, we provide passes identifying the HTTP endpoints and calls thereof.
Another pass (`HttpEndpointsBindingPass`) connect the HTTP calls with the respective endpoints.
The endpoints can be identified based on the libraries Pecan and WSGI, which are used by OpenStack.
!!! info “Configuration of the TOE”
For the configuration of the TOE, we also provide specific passes which model the values of the .ini files as `Concept`s and `Operation`s to simplify the identification thereof when mapping it to the source code.
!!! info “Dynamic Loading of the TOE’s Features”
Some TOEs such as OpenStack may have been developed with extensability in mind.
While this is a great feature, it significantly complicates the static analysis of the code base.
The heavy usage of dynamic loading of additional features and drivers through the custom library Stevedore makes it hard to statically analyze the code base and follow the flow through the program.
In particular, many security critical features and their integration depend on the configuration which is used to determine which drivers are loaded.
To address this, we provide a pass which connects the dynamic loading of drivers with the respective configuration and loads/instantiates additional modules and connects their functions according to the provided configuration.
Explicitly Stating Assumptions
Just as any other analysis tool, the Codyze Evaluator may introduce false positive and false negative findings. This can originate from errors in the implementation of the Codyze Evaluator (and the underlying CPG library), general limitations of the static analysis methods used, imprecision when tagging concepts and operations, unsupported features, ambiguous code snippets, or failing heuristics.
To address this, we explicitly state which assumptions have been made during the analysis, or have to be accepted to rely on the results of the Codyze Evaluator. While some assumptions have to hold on a global level (e.g., no bugs in the implementation of the Codyze Evaluator exist, the run of the Codyze Evaluator was not compromised, …), other assumptions (e.g., related to the correctness of certain translation on ambiguous code, known incomplete code, usage of heuristics) are specific to certain patterns in the TOE’s code. These are generated while constructing the CPG (in frontends, passes and the tagging logic) and are directly integrated into the CPG and linked to the node or edge which is affected by the assumption.
When querying the CPG, the assumptions which may affect the result (i.e., they are located on a path which is traversed) are returned as part of the result of the query.
Assumptions which are specific to an analysis method used to query the CPG and run the compliance checks, are not added to the CPG but still returned in the result of a query.
This provides a human evaluator with a good understanding of the limitations of the analysis, and the assumptions which have to be accepted to rely on the results. More importantly, the evaluator can perform a targeted assessment if the assumptions are valid for the given TOE, or if they can be accepted (depending on the EAL of the evaluation, some assumptions may simply not be relevant) and thus increase the trust into the Codyze Evaluators results. The evaluator can also reject assumptions which would resemble failing the automated analysis.
If an assumptions was accepted, this information is stored in a DSL and can thus be fed into subsequent runs of the Codyze Evaluator. With this technique, the assumptions do not have to be considered again and ultimately, a reproducible and understandable evaluation can be achieved. If an assumption cannot be accepted, the respective finding requires manual re-evaluation.
Running the Compliance Checks as Queries
The security claims of the TOE are expressed in the form of queries, which are executed on the CPG. The Codyze Evaluator traverses the CPG based on these queries and collects information about the nodes and edges which are relevant for the analysis. The result of a query expresses if the requirement holds for the given TOE. An extensive guideline on how to write queries is provided in the chapter How to write queries.
In short, a Query can access all information held in the CPG and is typically structured as follows: “for all nodes X in the graph, the property Y must hold” or “there must be at least one node X in the graph, for which the property Y holds”.
To identify X, the nodes in the CPG are traversed and filtered based on their type and optional pre-conditions provided in the query.
The property Y is the actual requirement and can be deducted from a PP, SF, SFR, best practices in coding, certain requirements of a specific implementation (e.g., library), or other sources of security goals. Frequent properties are a specific configuration of concepts and operations, or requirements on data flows and mandatory actions on each path in the execution. To simplify such queries, the CPG provides a set of methods to traverse the graph and perform reachability analyses.
The result of each query is a verdict if it holds together with a list of all steps which have been conducted to reach to this conclusion, as well as the assumptions which have to be accepted.
Summarized Workflow
In total, the internal workflow of the Codyze Evaluator can be summarized as follows: First, the source code is parsed to an abstract syntax tree (AST) and enriched by several passes to a CPG. Then, the tagging logic is applied to the CPG, which adds semantic information to the code and may trigger re-evaluating sub-graphs in the passes. This results in the final version of the CPG which is then used to run all the queries. These should no longer modify the graph to avoid any side effects. The results of the queries are collected and returned to the user.
User Roles and Skills
As there is a human involved in the workflow, we need to define the roles and skills of the human actor(s). We currently consider the following roles:
- An Codyze Evaluator Expert is a person with extensive knowledge on the Codyze Evaluator and its configuration. This person is able to write the Codyze Evaluator configuration and to interpret the results of the analysis. The Codyze Evaluator expert may also be involved in the development of new queries and security goals. The Codyze Evaluator expert may write custom Passes which enrich the CPG or could extend the Query API and provide novel analyses.
- A Domain Expert is a person with extensive knowledge in a certain domain, e.g., cryptography, or hardware-based security mechanisms. The domain expert is responsible for specifying requirements in the respective domain on a technical level but may not be able to write the rules for the Codyze Evaluator. The domain expert is also able to assess whether some findings of the Codyze Evaluators are valid and can validate or refute the findings and their underlying assumptions.
- An Evaluator is a person with extensive knowledge in the field of security evaluation and leads and supervises the evaluation. The evaluator may delegate technical assessments to the domain expert and customizing/configuring the Codyze Evaluator according to the requirements to the Codyze Evaluator Expert. However, the evaluator should be able to interpret the results of the Codyze Evaluator and write simple queries. The evaluator is responsible to assess the compliance of the TOE with respect to the security goals and claims.
- A Product Expert is a person with extensive knowledge of the concrete TOE spanning its components and configuration. The product expert should be able to point out implementation details of the TOE and describe how they relate to the security goals. The product expert may also be involved in the development of new queries and tagging the code with semantic concepts and operations.
Generalization
The Codyze Evaluator is designed to be extensible and customizable which makes it ideal to not only serve as a tool for evaluating OpenStack instances which is the current example but also for other software projects. The underlying CPG library already supports various programming languages, and provides the interface to add new languages easily. Hence, it is only necessary to adapt the Codyze Evaluator Configuration for a new project. This configuration can be adapted to assess the fulfillment of security goals in any software project. If the security goals (in terms of queries) are formulated in a general way, as it is the case for queries using concepts and operations, they can be applied to any software project with the same goals. Similarly, framework-specific tagging logic and queries (e.g., to check the correct usage of a certain framework) can be used across all projects which use the same framework.
Obviously, highly customized queries and tagging logic are not portable to other projects. This might be the case when using specific names of functions, classes, or variables of the respective project, or when relying on any other specific implementation details of the project.